深度学习中的配置系统
配置系统是很多深度学习套件和算法库的重要组件,一个优秀的配置系统可以方便用户修改训练所需的超参数、管理实验并且增强项目可读性等。配置系统不光可以用于大型的算法库,也可以用于个人进行快速实验和迭代。然而当前深度学习社区的配置系统都或多或少存在一些 不够方便 的地方,本文将会介绍一些已有的配置系统,并尝试对其进行改进。
YACS
YACS是一个轻量级的配置系统,Detectron和maskrcnn-benchmark便是使用的YACS,其使用可读性较好的YAML文件,格式为:
MODEL:
TYPE: mask_rcnn
CONV_BODY: FPN.add_fpn_ResNet50_conv5_body
NUM_CLASSES: 81
FASTER_RCNN: True
MASK_ON: True
该配置的第二行的TYPE为所要实例化的类,解析配置文件时若某个字典中包含TYPE,则表示应该将其实例化。
OpenMMLab
OpenMMLab系列的算法库提供了注册器(Registry)来维护了一个字符串到 类或函数的全局映射,这样便可以更加方便的通过字符串寻找到对应的类,使用方式为:
import torch.nn as nn
from mmengine import Registry
ACTIVATION = Registry('activation')
# 使用注册器管理模块
@ACTIVATION.register_module()
class Sigmoid(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
print('call Sigmoid.forward')
return x
然而随着codebase规模的不断增大,每次运行时会引入额外的注册开销和无关依赖。
OpenMMLab系列的算法库支持YAML,JSON和python作为配置文件,其中json和python的可读性奇差:
train_pipeline = [
dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}),
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
dict(type='RandomFlip', prob=0.5),
dict(
type='RandomChoice',
transforms=[[
dict(
type='RandomChoiceResize',
scales=[(480, 1333), (512, 1333), (544, 1333), (576, 1333),
(608, 1333), (640, 1333), (672, 1333), (704, 1333),
(736, 1333), (768, 1333), (800, 1333)],
keep_ratio=True)
],
[
dict(
type='RandomChoiceResize',
scales=[(400, 1333), (500, 1333), (600, 1333)],
keep_ratio=True),
dict(
type='RandomCrop',
crop_type='absolute_range',
crop_size=(384, 600),
allow_negative_crop=True),
]]),
dict(type='PackDetInputs')
]
PaddleDetection
PaddleDectetion的配置系统较为复杂且精妙,其只维护了一个全局的注册字典,配置文件格式如下:
metric: COCO
num_classes: 80
TrainDataset:
!COCODataSet
image_dir: train2017
anno_path: annotations/instances_train2017.json
dataset_dir: dataset/coco
data_fields: ['image', 'gt_bbox', 'gt_class', 'is_crowd']
不同于前面两种配置系统使用type,PaddleDetection使用yaml的representer实现通过!{}来获取python对象。此外PaddleDetection在实现类时添加了类属性——__shared__和__inject__,如:
from ppdet.core.workspace import register
@register
class BBoxPostProcess(object):
__shared__ = ['num_classes']
__inject__ = ['decode', 'nms']
def __init__(self, num_classes=80, decode=None, nms=None):
# 省略内容
pass
def __call__(self, head_out, rois, im_shape, scale_factor):
# 省略内容
pass
__shared__表示这些参数是全局共享的,__inject__表示这些参数是全局字典中已经封装好的模块,即实现了配置文件的嵌套,可谓十分之精妙了。
然而该配置系统过于定制化,不能很好的适应各种情况。
PaddleSeg
PaddleSeg中的配置格式并无特别之处,与前文相同,但是其解析、检查和构建对象都对进行了硬编码,这样的好处是编写代码时有补全。
LazyConfig
由于YAML和PYTHON配置文件一直被诟病不能跳转和补全,尤其是PYTHON,可读性更是一坨。detectron2提出了
LazyConfig,形式如:
import torch.nn as nnfrom detectron2.config import LazyCall, instantiate
# 通过LazyCall创建一个config对象
conv_config = LazyCall(nn.Conv2d)(in_channels=16, out_channels=16, kernel_size=3, stride=1, padding=1)
conv = instantiate(conv_config)
这里的conv_config将类对象和实例化所需参数都存储起来,等到需要实例化时才进行实例化,因此叫做Lazy。这样编写配置文件时可以为对应的类提供补全和跳转,并且通过该方式可以直接舍弃注册器,可谓是一箭双雕。
然而该配置系统不能对类的参数进行补全和检查。
OpenMMLab python config
同样为了支持跳转和补全,OpenMMLab提供了新式的python配置文件——即将type后的字符串变为类,可读性仍然是一坨,远没有detectron2优雅。
ExCore
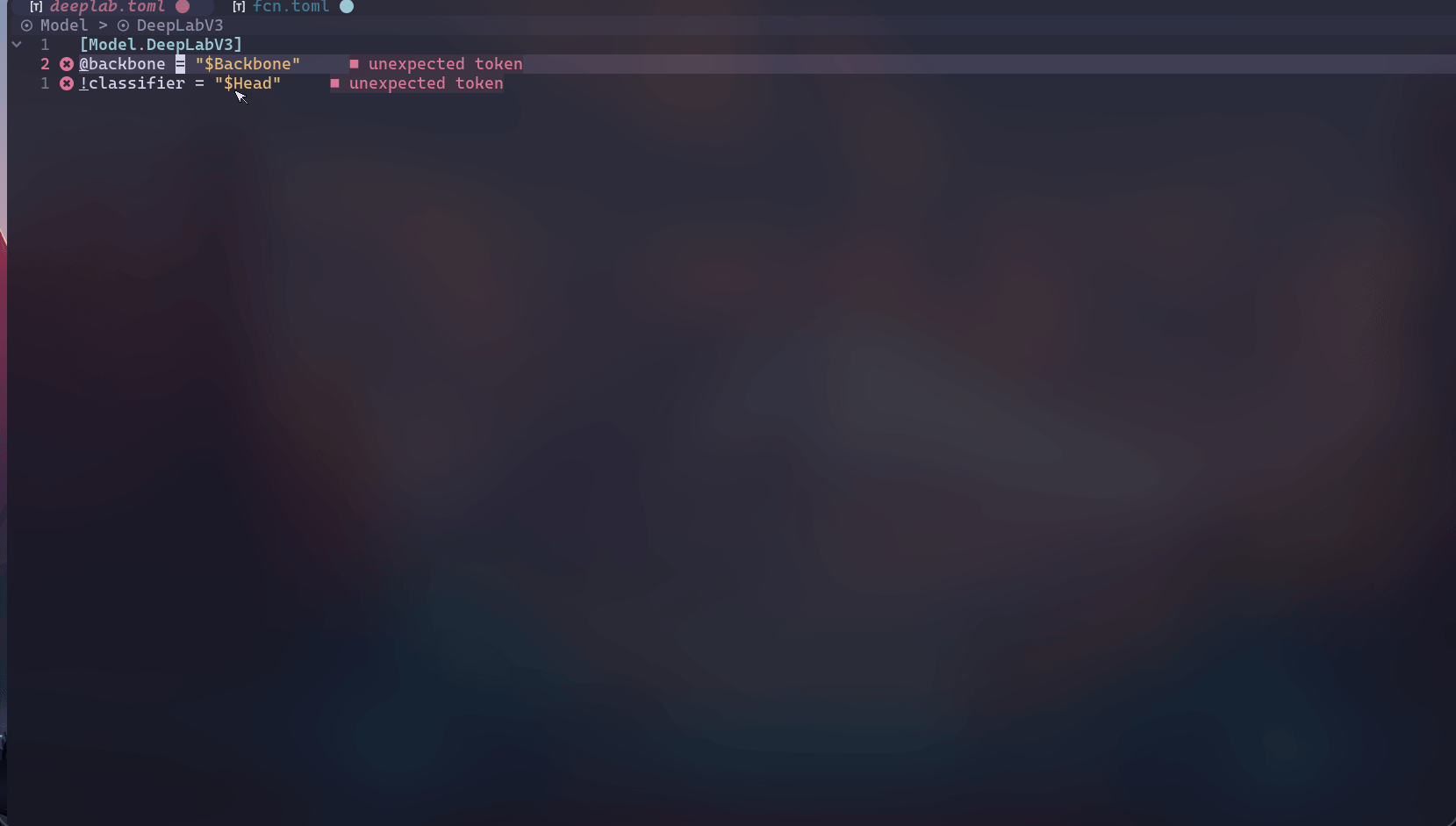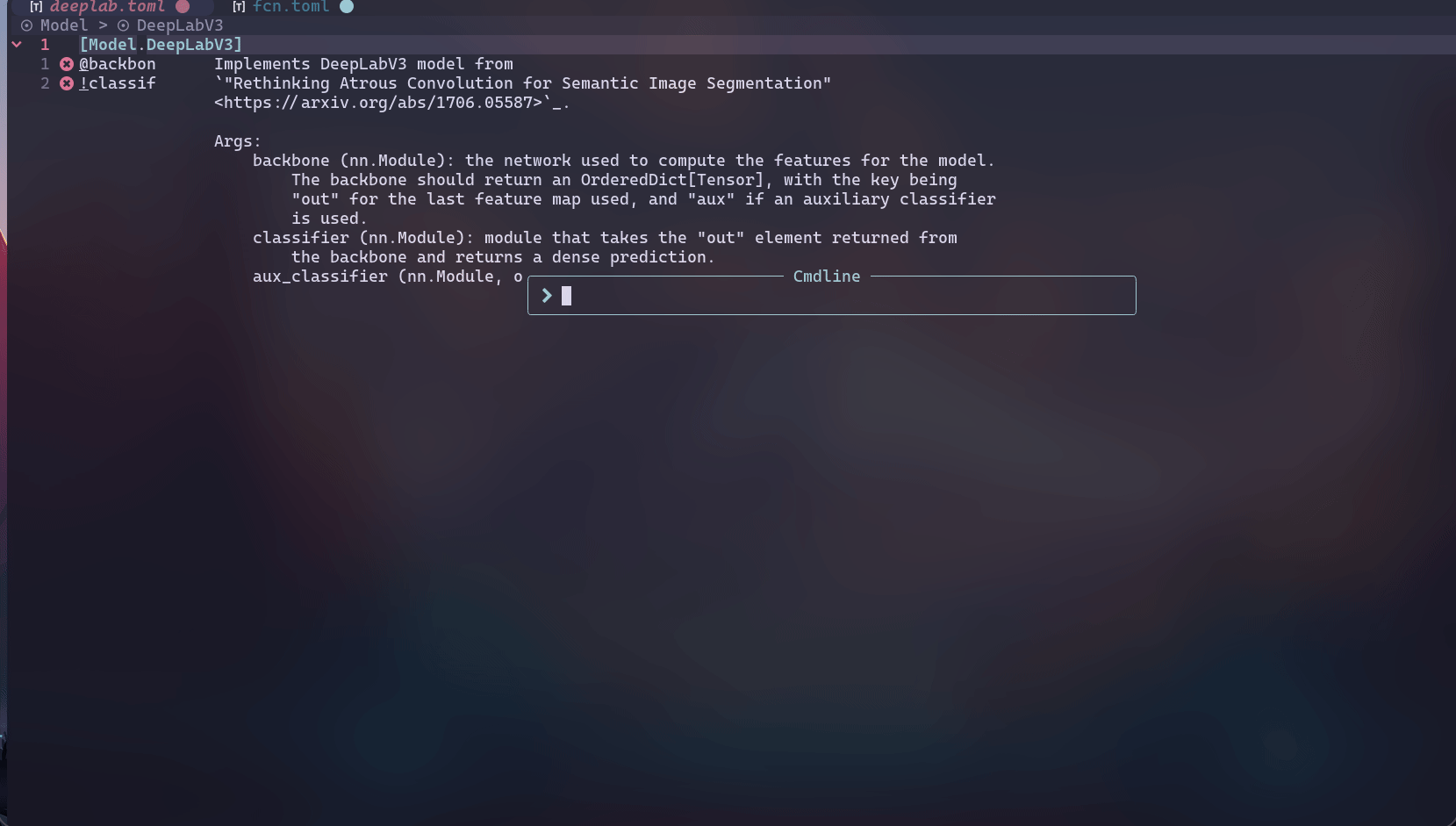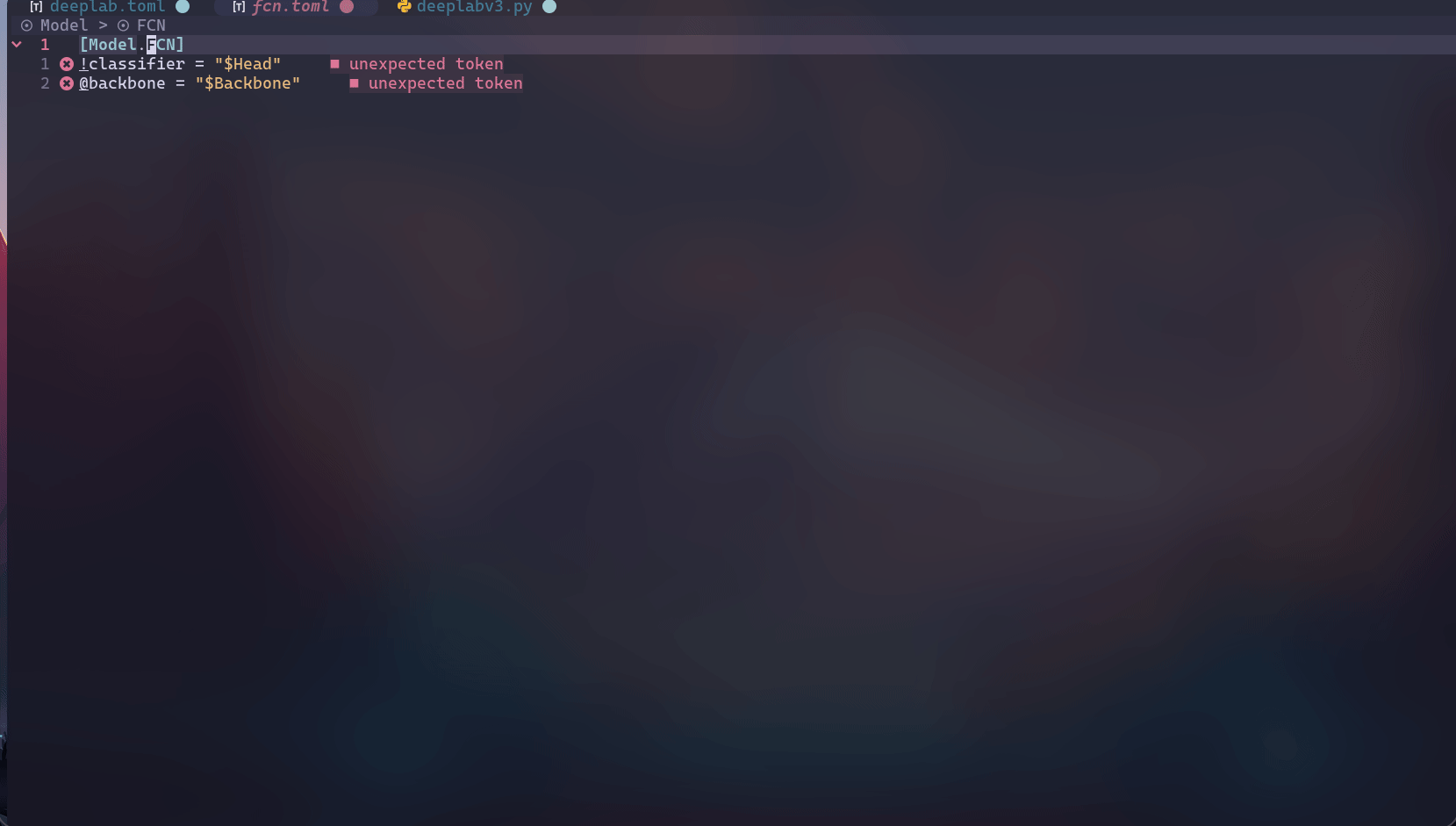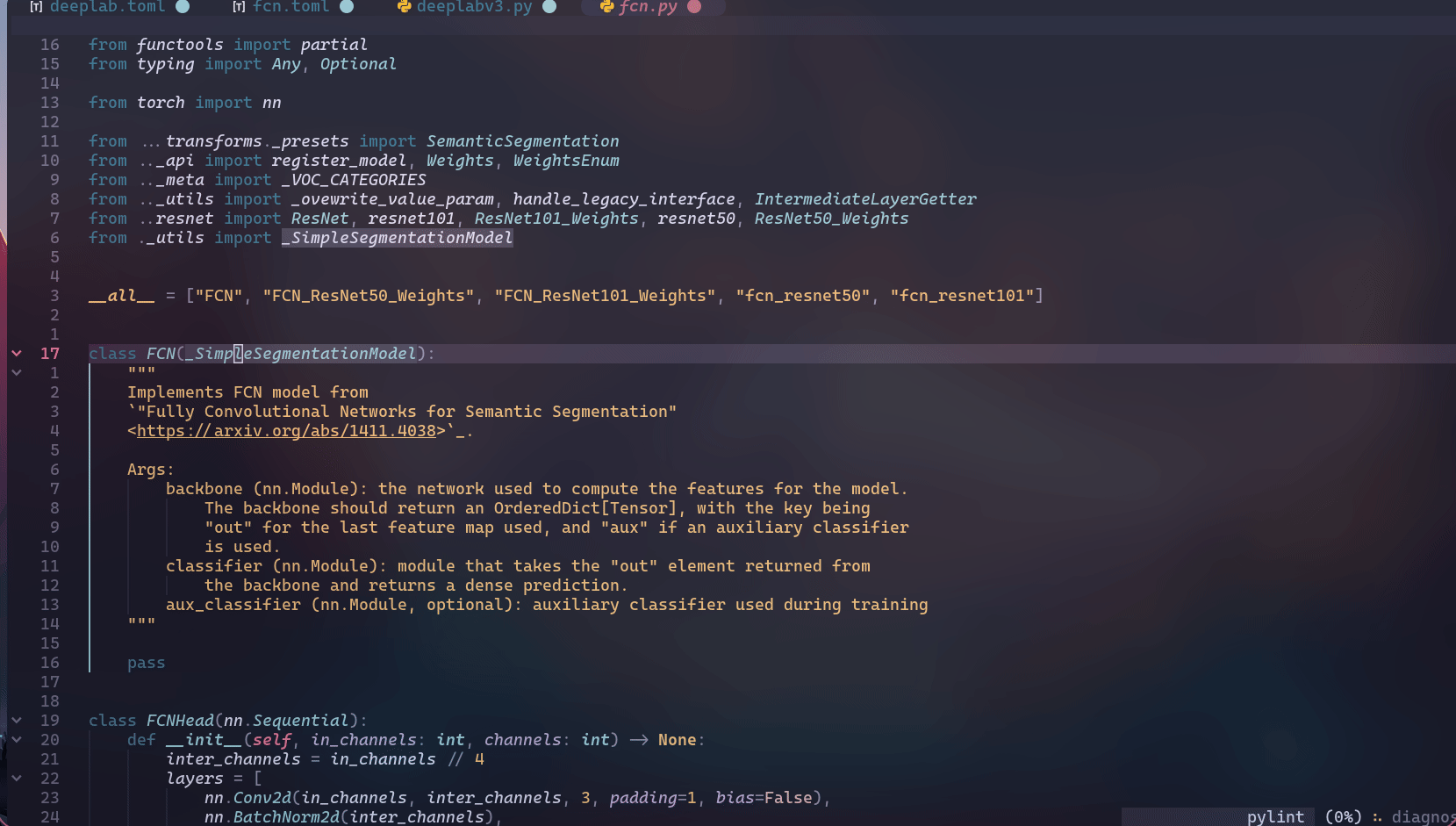
为了一定程度上解决上述问题,我开发了ExCore,主要用于个人的实验。ExCore使用TOML作为配置文件,并且借助LSP(language server protocol)的力量在一定程度上弥补了配置文件和python文件之间的鸿沟——即为TOML配置文件提供了补全、跳转、查看文档、参数检查等功能,先看几个动图再介绍。 补全,查看文档和参数检查:
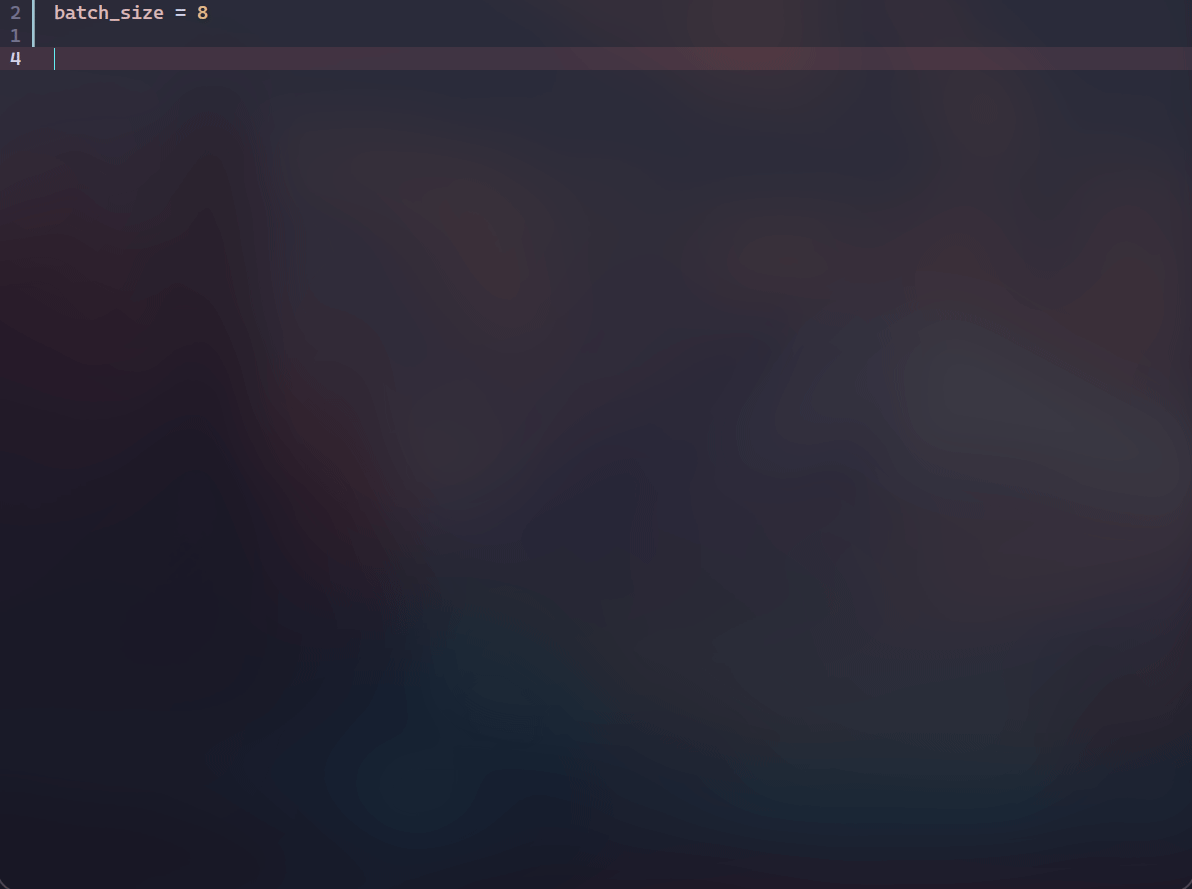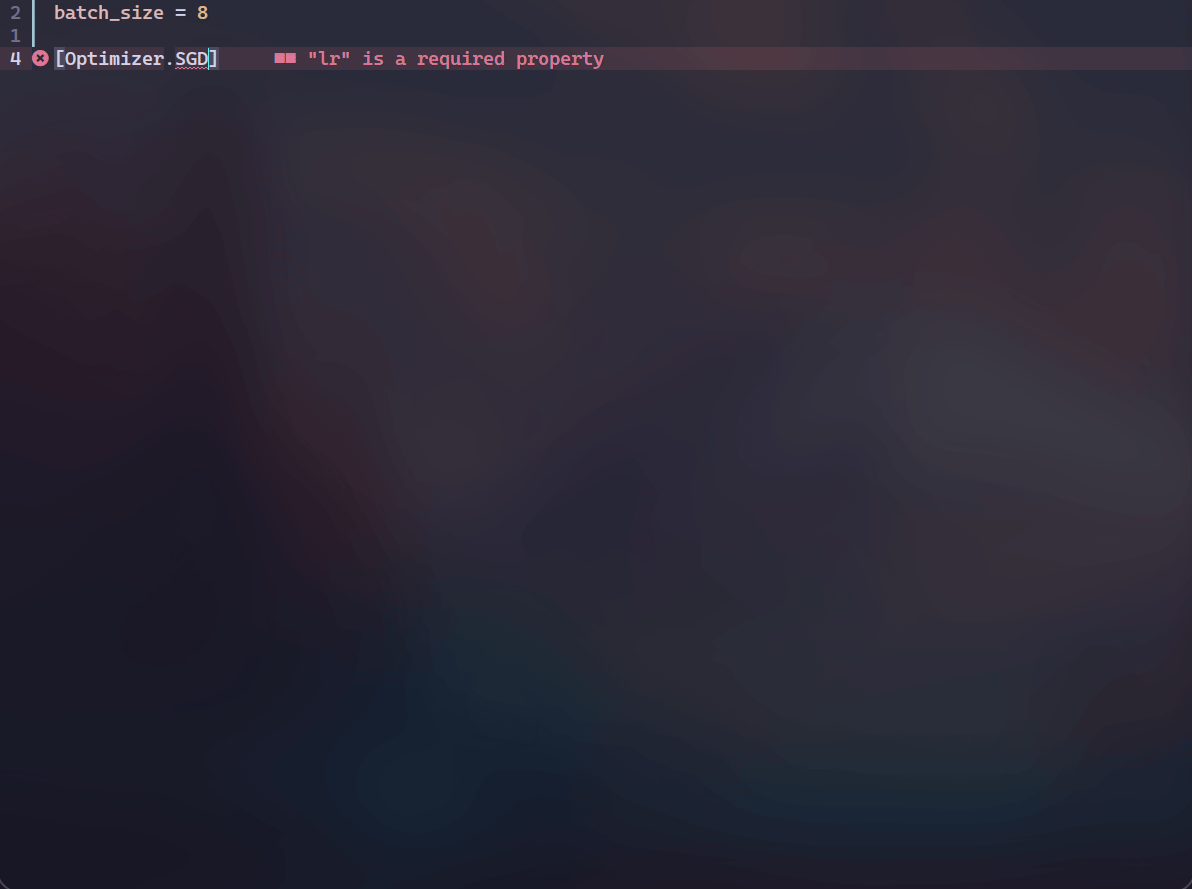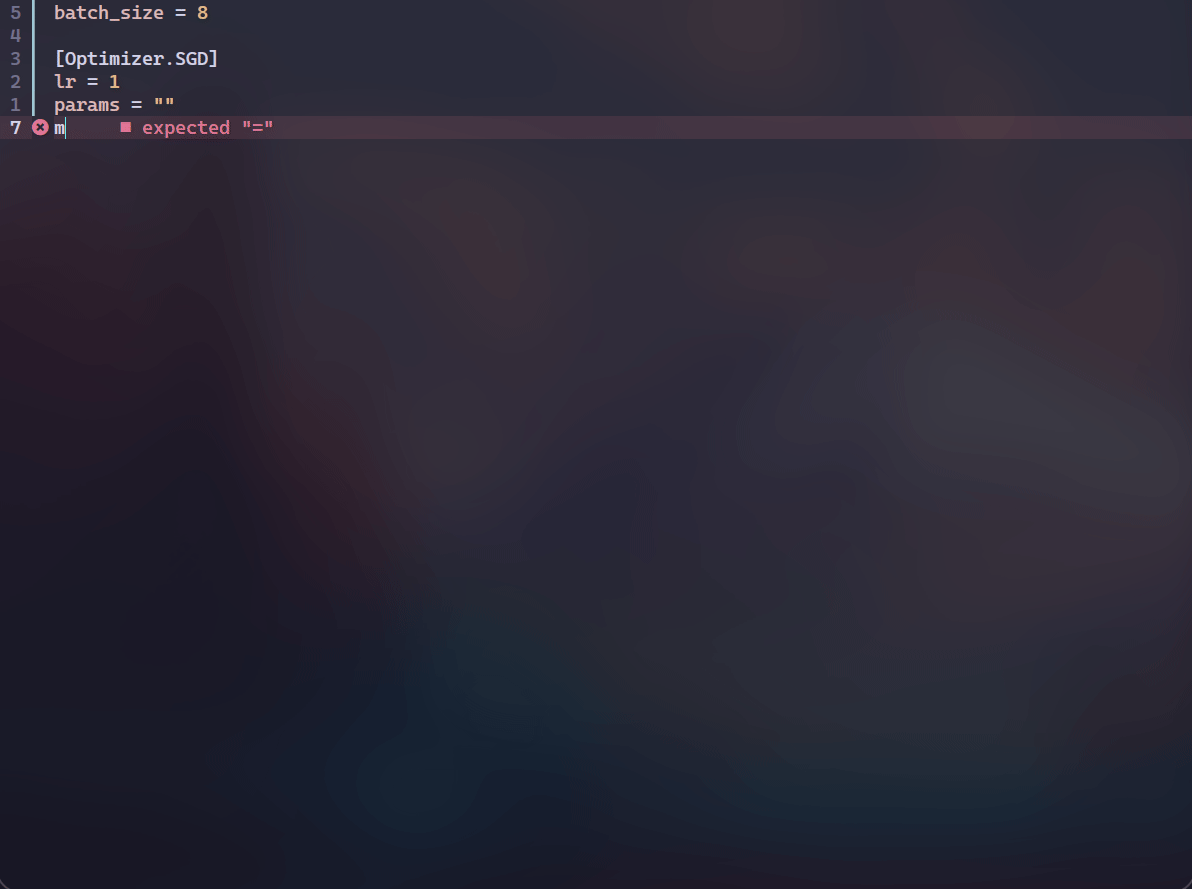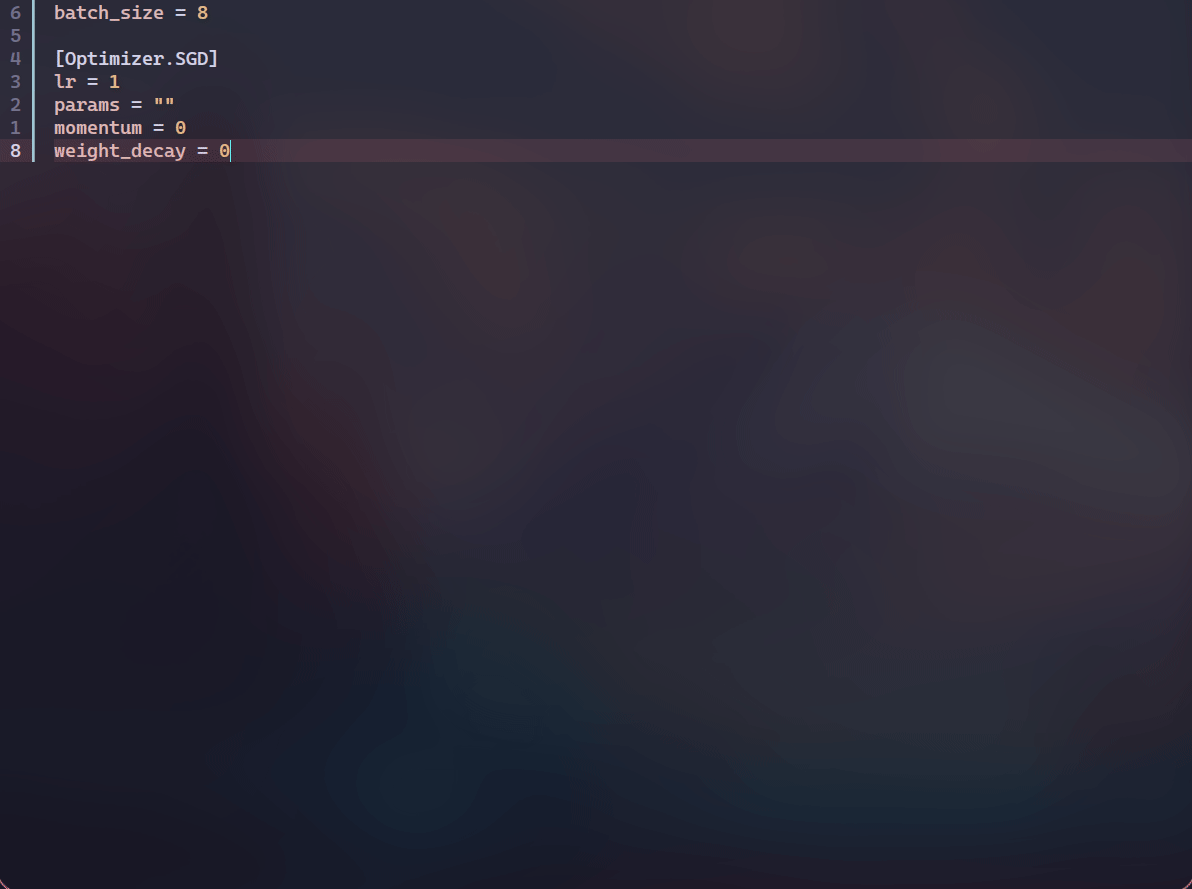
可以看到会有类名及其参数的补全以及查看对应类的docstring,并且会对required参数进行提示。
跳转:
跳转以插件的形式实现,目前仅支持NeoVim,见excore.nvim
基本概念
本配置系统的核心前提是将配置文件中所要创建的对象分为三类—— 主要、 中间 和 孤立 对象。
主要对象是指在训练中 直接 使用的对象,如模型、优化器等。ExCore会创建并返回这些对象。中间对象是指在训练中 间接 使用的对象,如模型的主干、将要传入优化器的模型参数。孤立对象是指 python 内建对象,会在读取配置文件时直接解析,如 int, string, list, dict 等
配置文件格式
ExCore 扩展了 toml 文件的语法,引入了一些特殊的前缀字符 —— !, @, $ 和 & 以简化配置文件的定义过程,因此配置文件格式为:
size = 224
[TrainData.ImageNet]
&train_size = "size"
!transforms = ['RandomResize', 'Pad']
data_path = 'xxx'
[Transform.Pad]
&pad_size = "size"
[TestData.ImageNet]
!transforms = 'Normalize'
&test_size = "size"
data_path = 'xxx'
这里的TrainData,TestData是一个字典,其元素都是上文所提到的主要对象,可以称之为主要模块,主要 模块需要定义为 [PrimaryFields.ModuleName]. PrimaryFields 是一些预先定义的字�段, 这里即是TrainData, TestData, ModuleName 即为注册的名称, 这里即为ImageNet和 Pad. 如此便可以去除type。
第四行的&表示引用,即train_size的值最终会被解析为224。
第五行的!表示该参数并不是python built-in对象,即类似于配置嵌套,注意这里的RandomResize, 如果其没有参数,则可以不在配置文件中声明。等价的yaml文件为:
TrainData:
type: ImageNet
train_size: 224
data_path: 'xxx'
transforms:
- type: RandomResize
pad_size: 224
- type: Pad
TestData:
type: ImageNet
test_size: 224
data_path: 'xxx'
transforms:
- type: Normalize
此外@用于表示共享模块,如:
[Model.FCN]
@backbone = "ResNet"
[Model.SegNet]
@backbone = "ResNet"
[ResNet]
layers = 50
in_channel = 3
这里的FCN和SegNet的bacbone将会是同一个对象。
$则用于表示不需要实例化,这是一个类,如:
[Model.ResNet]
$block = "BasicBlock"
layers = 50
in_channel = 3
该功能上文介绍的注册系统是无法实现的。
$除了用于参数名之前,还可以用于��参数值之前,后跟PrimaryFields,如:
__base__ = ["./block.toml"]
[Model.ResNet]
!block="$Block"
该功能用于跨文件使用,即会在所有加载的配置文件中找到Block字段,将其值传入。
同样为了方便使用,本配置系统提供了一套参数级别的HOOk,如最常见的将模型的参数传入优化器,格式为:
[Optimizer.AdamW]
@params = "$Model.parameters()"
weight_decay = 0.01
这也是上文所有配置系统所做不到的。
如果你想调用类方法或静态方法,可以:
[Model.XXX]
$backbone = "A.from_pretained()"
也可以获取属性,就像写python一样即可,但是不可传入参数:
[Model.XXX]
@channel = "$Block.last_conv.out_channels"
借助该功能我们可以注册模块,如:
[Model.ResNet]
$activation = "torch.nn.ReLU"
更复杂的情况可以继承ExCore提供的hook基类:
[Optimizer.SGD]
@params = "$Model@BnWeightDecayHook"
lr = 0.05
momentum = 0.9
weight_decay = 0.0001
[ConfigHook.BnWeightDecayHook]
weight_decay = 0.0001
bn_weight_decay = false
enabled = true
使用@BnWeightDecayHook来将$Model传入hook中
Hook类定义:
from excore.engine.hook import ConfigArgumentHook
from . import HOOKS
@HOOKS.register()
class BnWeightDecayHook(ConfigArgumentHook):
def __init__(self, node, enabled: bool, bn_weight_decay: bool, weight_decay: float):
super().__init__(node, enabled)
self.bn_weight_decay = bn_weight_decay
self.weight_decay = weight_decay
def hook(self):
model = self.node()
if self.bn_weight_decay:
optim_params = model.parameters()
else:
p_bn = [p for n, p in model.named_parameters() if "bn" in n]
p_non_bn = [p for n, p in model.named_parameters() if "bn" not in n]
optim_params = [
{"params": p_bn, "weight_decay": 0},
{"params": p_non_bn, "weight_decay": self.weight_decay},
]
return optim_params
配置文件补全、检查和查看文档
实际上是利用json_schema曲线救国,ExCore对所有注册的类进行静态分析和类型推断,因此对type-hinting的要求比较高,如果没有编写type-hinting,则会根据默认值进行推断。将结果缓存在本地,由TOML对应的LSP完成该功能。
跳转
在上一步静态分析的过程中,将类名及其文件地址缓存在本地,针对不同的编辑器实现插件。
简单的API
不同于上述的配置系统需要额外的构建系统,ExCore仅仅提供两个API用于加载、解析配置文件以及实例化:
from excore import config
lazy_cfg = config.load('xxx.toml')
modules, run_info = config.build_all(lazy_cfg)
这里的modules是一个wrapper,可以通过预先定义的主要字段来获取构建的模块,如要获得Model,只需要:
model = modules.Model
但是目前还不支持补全,后续可以根据主要字段自动生成一个类专门用作type-hinting,例如:
class ModuleWrapper:
Model: Any
modules: ModuleWrapper
model = modules.Model
run_info中存储的则是之前提到的孤立对象,是一个字典。
LazyConfig
ExCore同样支持python形式的配置文件,与detectron2基本一致,不过实例化时只需调用__call__方法即可,如下:
from excore.config.models import ModuleNode
from xxx import Module
cfg = ModuleNode(Module) << dict(arg1=1, arg2=2)
# or
cfg = ModuleNode(Module).add(arg1=1, arg2=2)
model = cfg() # support instantiate recursively
# or
model = ModuleNode(Module)(arg1=1, arg2=2)
实际上上文中lazy_config = config.load('xxx.toml')就是将配置文件解析为了一系列LazyConfig对象,可以对其进行一些操作(如通过命令行替换参数),再使用build_all进行实例化。
LazyRegistry
Registry在当今看来并不是一个很好的设计,但出于某些考虑和原因,我实现了一种我称之为LazyRegistry的注册机制,同样能够避免冗余的注册和依赖。ExCore中的Registry更多起的是一种标记的作用,用于实现配置文件的补全、提示和跳转。后面有空再详细介绍。